Ancient white text recognition algorithm based on partial label learning
A recognition algorithm and Baiwen technology, applied in the field of ancient Baiwen recognition, can solve the problems of slow recognition speed, affect the recognition efficiency of ancient Baiwen, and it is difficult to guarantee the accuracy of recognition, and achieve the effect of low cost, convenient acquisition and high algorithm efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

Examples
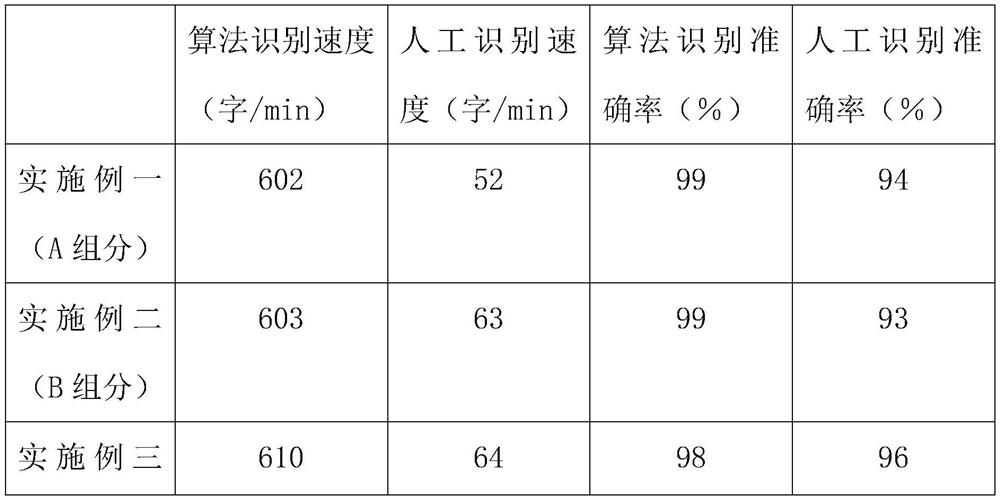
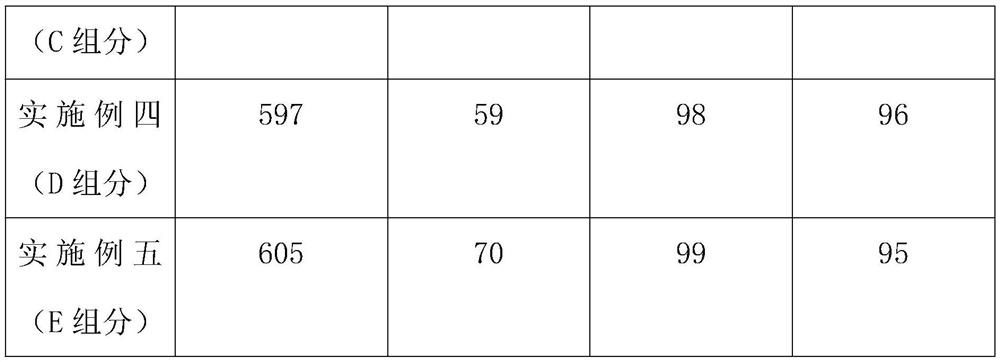
Embodiment 1
[0042] The ancient Baiwen recognition algorithm based on partial label learning includes the following steps:
[0043] Step 1: first input the recognition algorithm formula inside the recognition device: input D={(X i , S i )丨1≤i≤m}: Partially labeled data training set, enter the recognition formula again: D * ={x i 丨1≤i≤m *}, this is the partially labeled data test set;
[0044] Step 2: Use two formulas to carry out forward label propagation weights, and then carry out reverse label propagation weights;
[0045] Step 3: Use the formula to correct the initial confidence weight, set k as the number of nearest neighbor samples, and T as the number of label propagation iterations;
[0046] Step 4: Output, y i For the training set example x i Disambiguation results, where 1≤i≤m, output y i * For the test set example x i * The classification results of , where 1≤i≤m * .
[0047] Step 5: Obtain the k-nearest neighbor relationship of each example, and solve the connection w
Embodiment 2
[0059] The ancient Baiwen recognition algorithm based on partial label learning includes the following steps:
[0060] Step 1: first input the recognition algorithm formula inside the recognition device: input D={(X i , S i )丨1≤i≤m}: Partially labeled data training set, enter the recognition formula again: D * ={x i 丨1≤i≤m *}, this is the partially labeled data test set;
[0061] Step 2: Use two formulas to carry out forward label propagation weights, and then carry out reverse label propagation weights;
[0062] Step 3: Use the formula to correct the initial confidence weight, set k as the number of nearest neighbor samples, and T as the number of label propagation iterations;
[0063] Step 4: Output, y i For the training set example x i Disambiguation results, where 1≤i≤m, output y i * For the test set example x i * The classification results of , where 1≤i≤m * .
[0064] Step 5: Obtain the k-nearest neighbor relationship of each example, and solve the connection w
Embodiment 3
[0076] The ancient Baiwen recognition algorithm based on partial label learning includes the following steps:
[0077] Step 1: first input the recognition algorithm formula inside the recognition device: input D={(X i , S i )丨1≤i≤m}: Partially labeled data training set, enter the recognition formula again: D * ={x i 丨1≤i≤m *}, this is the partially labeled data test set;
[0078] Step 2: Use two formulas to carry out forward label propagation weights, and then carry out reverse label propagation weights;
[0079] Step 3: Use the formula to correct the initial confidence weight, set k as the number of nearest neighbor samples, and T as the number of label propagation iterations;
[0080] Step 4: Output, y i For the training set example x i Disambiguation results, where 1≤i≤m, output y i * For the test set example x i * The classification results of , where 1≤i≤m * .
[0081] Step 5: Obtain the k-nearest neighbor relationship of each example, and solve the connection w
PUM
 Login to view more
Login to view more Abstract
Description
Claims
Application Information
 Login to view more
Login to view more - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap