Method and device for training word vector model
A technology of word vector and model, applied in the field of deep learning, can solve the problem of low accuracy of word vector, and achieve the effect of improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

Examples
Embodiment 1
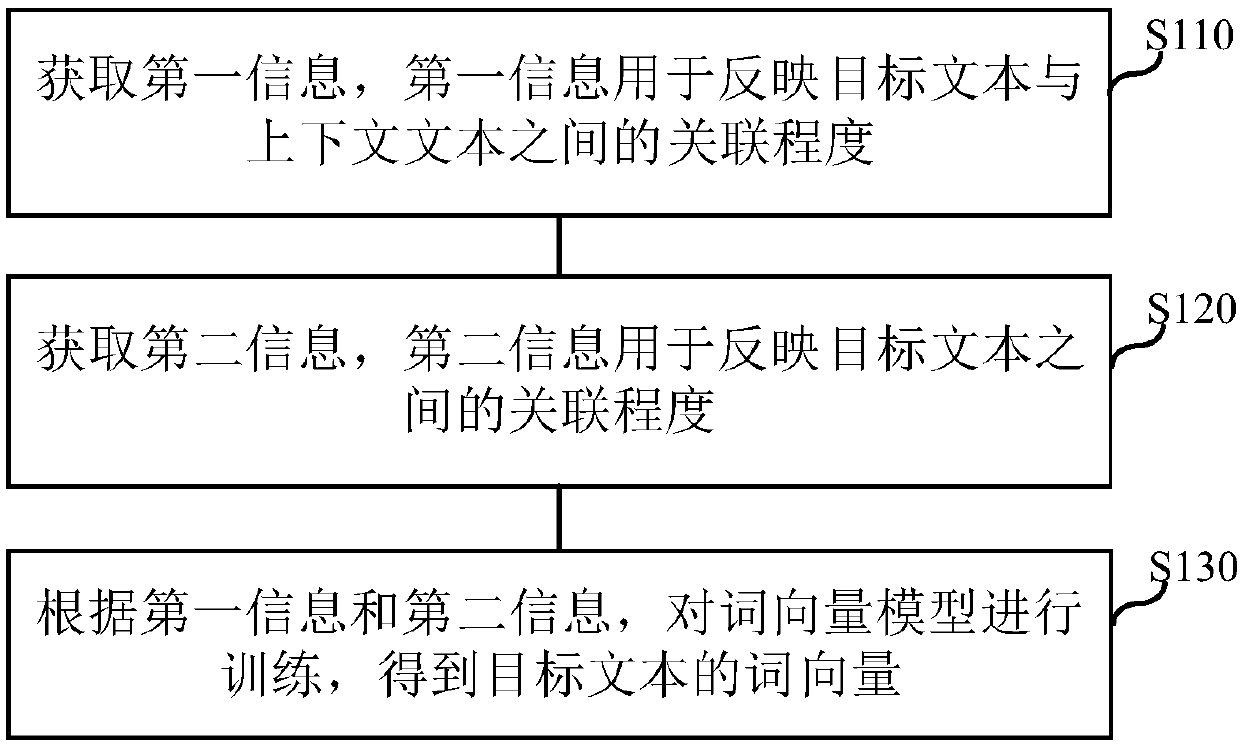
[0052] The embodiment of the present application provides a method for training a word vector model, such as figure 1 shown, including:
[0053] Step S110: Obtain statistical information of text information in the text library, where the text information includes target text and context text. Specifically, the text information in the text database may be words, phrases, or n-grams in natural language, which is not limited in this application. The statistical information is first-order co-occurrence information, and specifically may be a co-occurrence matrix.
[0054] Further, the number of words in the dictionary can be 50,000, 100,000, 200,000, etc. When the number of words in the dictionary is 100,000, these 100,000 words will form a 100,000-line 100,000 A two-dimensional matrix of columns, where the value of row i and column j represents the co-occurrence statistics of vocabulary i and vocabulary j, that is, the number of times vocabulary i and vocabulary j co-occur in the t
Embodiment 2
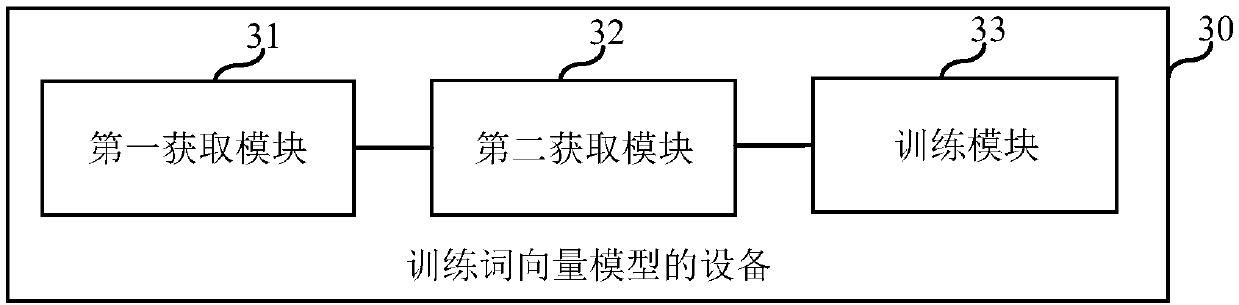
[0063] The embodiment of the present application provides another possible implementation mode. On the basis of the first embodiment, the method shown in the second embodiment is also included, wherein,
[0064] Step S130 may include step 1301 (step not marked): using statistical information and point mutual information distribution overlapping information as training data, based on the target loss function, to train the preset word vector determination model.
[0065] At this time, it is joint training, that is, according to the first-order co-occurrence information, based on the first loss function, the first loss amount is obtained; according to the second-order co-occurrence information, based on the second loss function, the second loss amount is obtained; according to the first loss The amount and the second loss amount are used to train the word vector model.
[0066] Step S111 (not marked in the figure) is also included before step S130: determining the target loss functi
Embodiment 3
[0094] The embodiment of the present application provides another possible implementation manner. On the basis of the second embodiment, the method shown in the third embodiment is also included, wherein,
[0095] Step S120 may include step S1201 (not marked in the figure), step S1202 (not marked in the figure), step S1203 (not marked in the figure) and step S1204 (not marked in the figure), wherein,
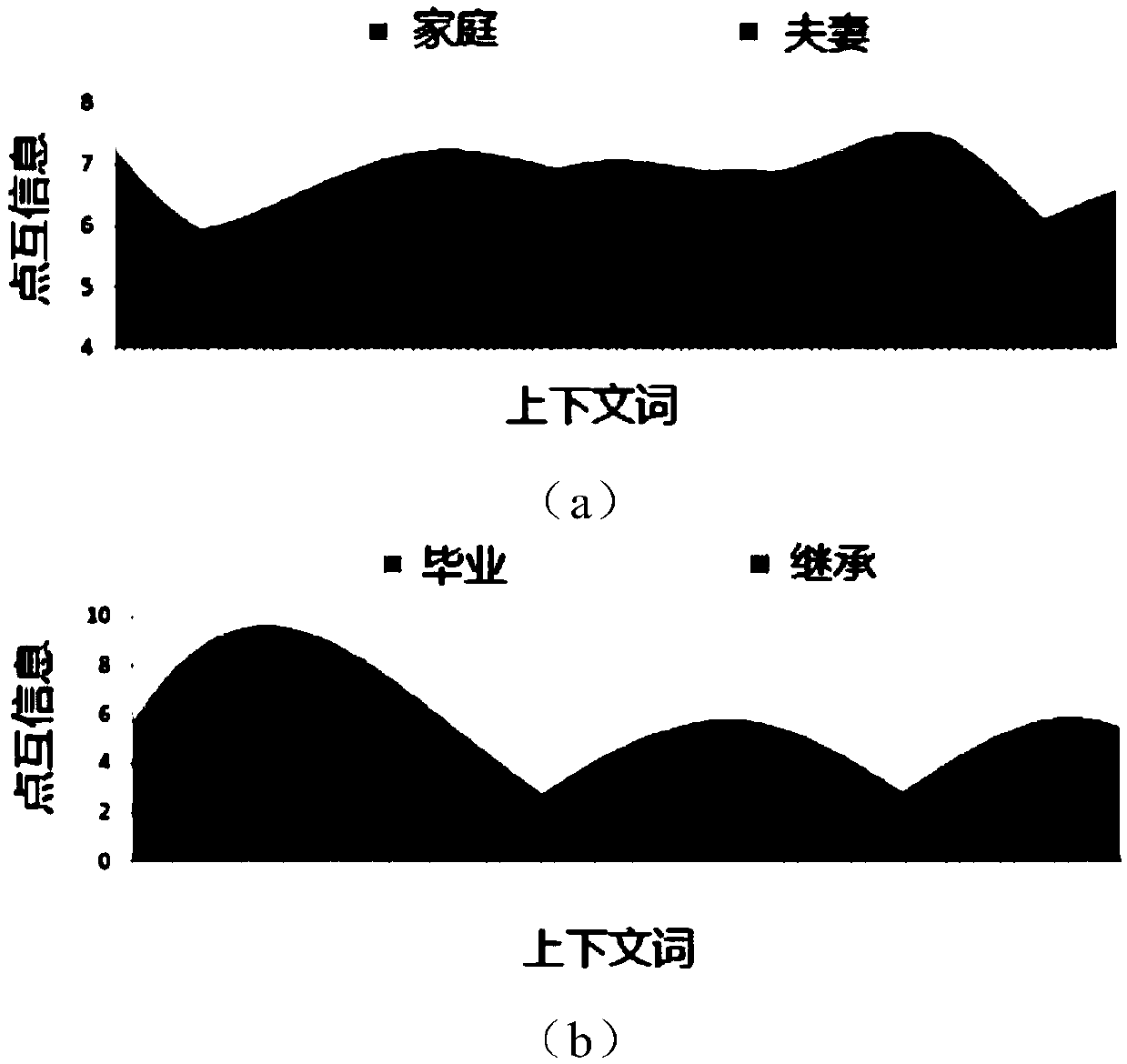
[0096] Step S1201: Determine the context text sets corresponding to each target text;
[0097] Step S1202: According to each context text set, determine the intersection between any two context text sets;
[0098] Step S1203: According to the determined intersection between any two context text sets, determine the point mutual information between each target text and the context text in the intersection;
[0099] Step S1204: According to the determined point mutual information between each target text and the intersection, determine distribution overlap information, and obtain the
PUM
 Login to view more
Login to view more Abstract
Description
Claims
Application Information
 Login to view more
Login to view more - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap