Neural network visual dialogue model and method based on KR product fusion multi-modal information
A neural network, multimodal technology for visual dialogue and multimodal fusion
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

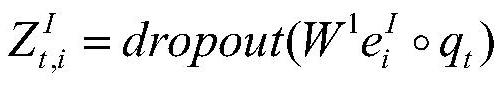
Examples
Embodiment Construction
[0030] The present invention will be described in further detail below in conjunction with the accompanying drawings and specific embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
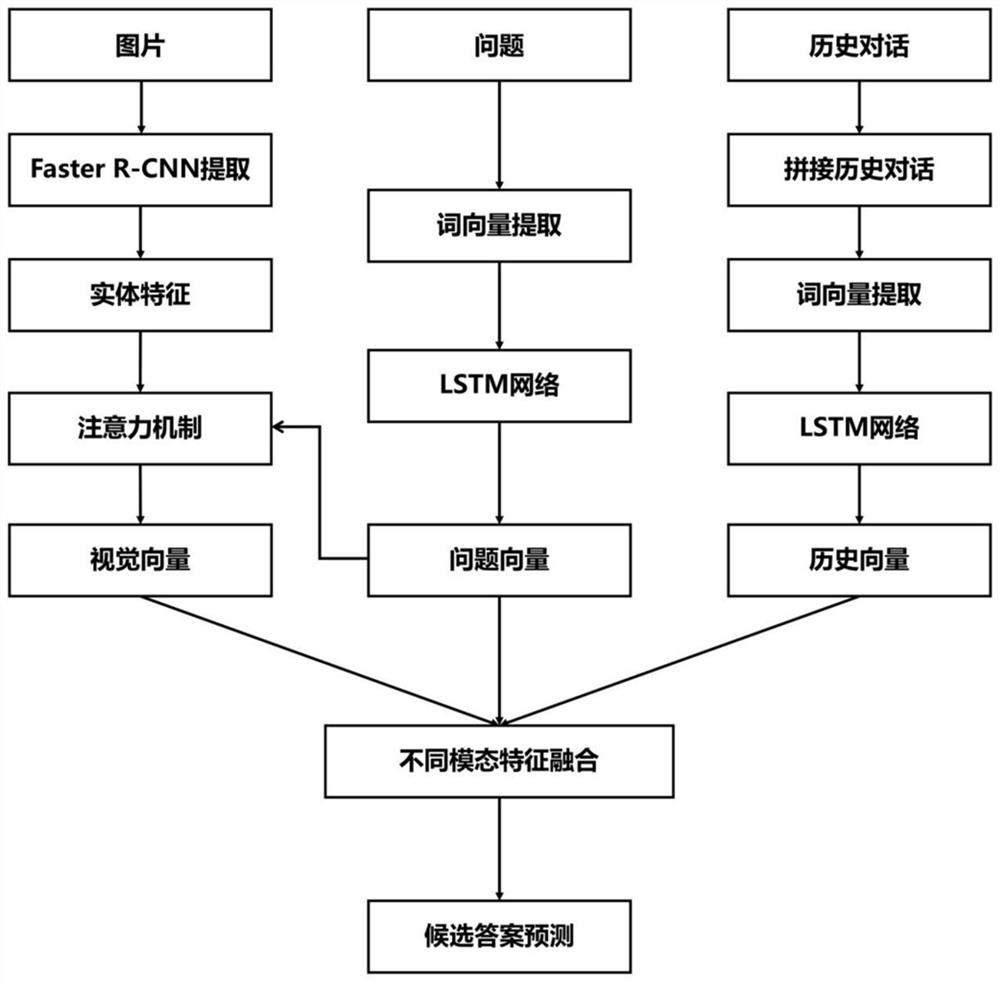
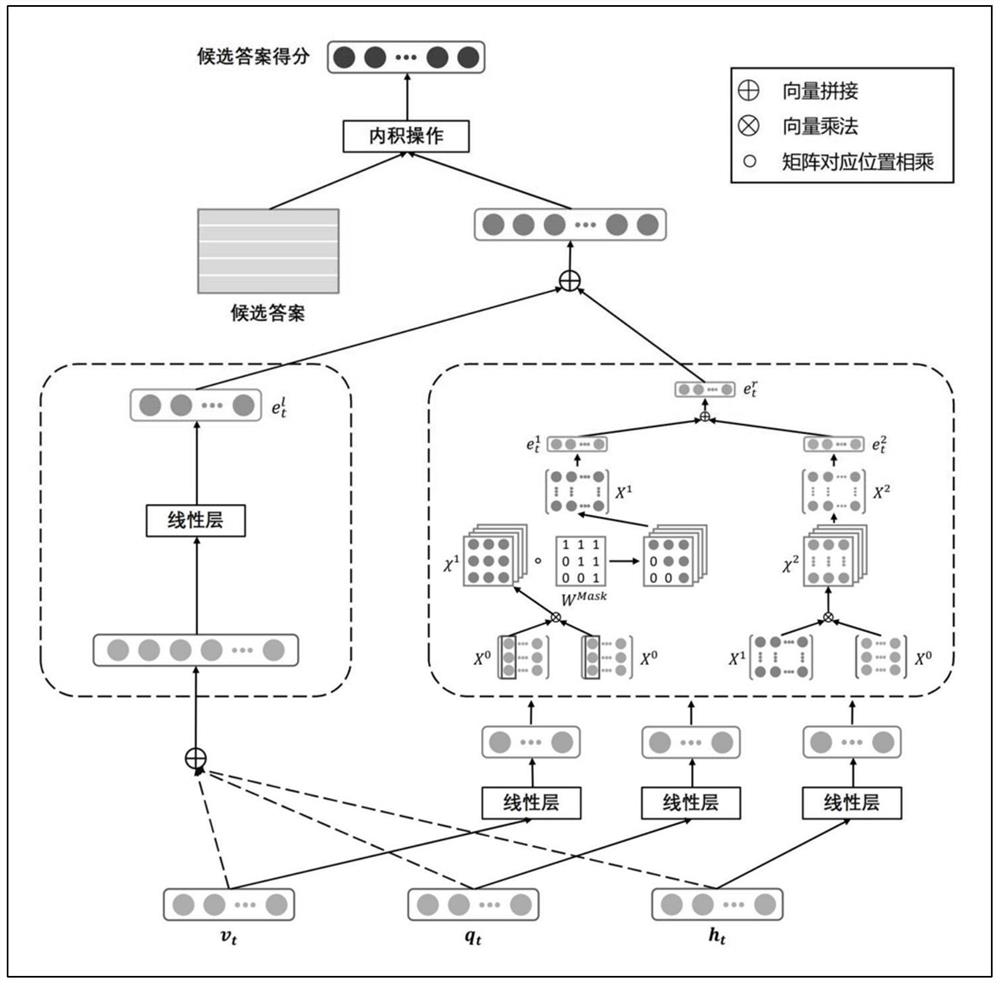
[0031] A neural network visual dialogue model based on KR product fusion of multi-modal information, including a modal feature extraction module, a different modal information fusion module and a candidate answer prediction module;
[0032] The modality feature extraction module is used to extract the semantic features of questions, the visual features of images and the historical features of historical dialogues. First, the vector representation of the question is obtained through the LSTM network, and a set of entity feature vectors of the image are obtained using the Faster R-CNN network. The historical dialogue information is regarded as a whole or the content of each round of dialog
PUM
 Login to view more
Login to view more Abstract
Description
Claims
Application Information
 Login to view more
Login to view more - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap